Blog
- Medical Devices Regulation: for AI systems in medical devices;
- Constitutions + Human Rights Treaties: for protection of fundamental rights such as freedom of speech, privacy and self-determination;
- General Data Protection Regulation: when personal data is processed;
- Product safety regulations: when an AI system causes injury;
- Consumer protection: when information obligations arise from these regulations;
- Codes of conduct: when rules (code of conduct) have been established in a sector for AI systems, and
- Contracts: when parties have established rules for AI systems in an agreement.
LegalAIR
General information about legal aspects of AI can be found on ourAI compliance assessment
For this reason, it is wise for both developers and users of AI systems to determine with an AI compliance assessment which laws and regulations apply to their AI system and whether they are compliant. If they are not met, timely measures can be taken to become compliant. For more questions about this, or for guidance on the performance of an [post_title] => We already have rules for AI systems
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => we-already-have-rules-for-ai-systems
[to_ping] =>
[pinged] =>
[post_modified] => 2021-11-08 14:12:34
[post_modified_gmt] => 2021-11-08 13:12:34
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=27650
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[2] => WP_Post Object
(
[ID] => 27500
[post_author] => 78
[post_date] => 2021-10-28 15:06:10
[post_date_gmt] => 2021-10-28 13:06:10
[post_content] => In recent years,
[post_title] => We already have rules for AI systems
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => we-already-have-rules-for-ai-systems
[to_ping] =>
[pinged] =>
[post_modified] => 2021-11-08 14:12:34
[post_modified_gmt] => 2021-11-08 13:12:34
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=27650
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[2] => WP_Post Object
(
[ID] => 27500
[post_author] => 78
[post_date] => 2021-10-28 15:06:10
[post_date_gmt] => 2021-10-28 13:06:10
[post_content] => In recent years, What is synthetic data?
Synthetic data are artificially created data that contain many of the correlations and insights of the original dataset, without directly replicating any of the individual entries. This way, data subjects should no longer be identifiable within the Example of a use case for synthetic data.
Example of a use case for synthetic data.
Anonymisation versus pseudonymisation
- Singling out: the possibility to distinguish and identify certain individuals within the dataset.
- Linkability: the ability to link two or more datapoints concerning the same data subject within one or more different datasets.
- Inference: the possibility to deduce, with significant probability, the value of an attribute from a data subject by using the values given to other attributes within the dataset.
Not completely exempt from the GDPR
However, this does not mean that the safeguards of theThings to keep in mind
Generating synthetic data has a lot of potential, as long as the process is implemented correctly. If you are considering to utilize synthetic data, please take note of the following- Evaluate whether synthetic data offers a suitable solution for the specific needs of your business or organization. The main advantage of synthetic data lies in their ability to preserve the statistical properties of the original dataset. This attribute provides a lot of utility in certain use cases, such as compute learning and (scientific) research.
- Assess whether the synthetic datasets deviate enough from the original datasets and adjust the settings of the AI-systems accordingly. In doing so, pay attention to the criteria as laid down by the WP29.
- Give thought to your obligations under the GDPR. List your lawful basis for processing, as well as the purpose for which this is done.
What does it mean exactly?
Often there are already laws and regulations that apply to AI applications. Such as, for example, the General Data Protection Regulation, the Medical Device Regulation, the Constitution/Charter of Fundamental rights of the European Union and product liability regulations. But for many aspects, there is still no regulation. There is regulation to come, like the proposal for a European AI Regulation. See our blog about this proposal. In an AI Risk Assessment, we- legal – all applicable laws and regulations are complied with;
- ethical – ethical principles and values are respected;
- robust – the AI application is robust both from a technical (cyber security) and a social point of view
How it works
To carry out the AI Risk Assessment, we use a model in which we take the following steps:- performing a pre-test: is it necessary to perform an AI Risk Assessment? If the risks are very limited, then perhaps it is not necessary to perform an AI Risk Assessment.
- Performing Risk Assessment: together with the client, we determine in advance the team of the client with whom we carry out the assessment, how we will carry it out, whether external parties will be part of the team (ethicists, information security experts, etc.).
- After the assessment, the client receives a report in which we have outlined the risks of the AI application in question with recommendations on how risks can be mitigated.
- After measures have been taken in which risks have been mitigated, we can carry out the AI Risk Assessment again and issue a new report.
Why have bg.legel perform the AI Risk Assessment?
BG.legal has a team consisting of lawyers and a data scientist, which focuses on the legal aspects of data/AI. We have advised clients on these topics for several years. Our clients are companies (startups, scale-ups and SMEs), governments and knowledge institutions. Sometimes they develop AI applications and sometimes they have AI applications developed or they are a customer/user of an AI application.What does it cost?
The costs of performing an AI Risk Assessment depend on the nature and size of the AI application. After an initial meeting, we will make a quotation for the costs.More information?
For more information, please contact Jos van der Wijst: M : +31 (0)650695916 E : wijst@bg.legal [post_title] => Risk check for AI applications
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => risk-check-for-ai-applications
[to_ping] =>
[pinged] =>
[post_modified] => 2021-11-29 16:15:04
[post_modified_gmt] => 2021-11-29 15:15:04
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=26698
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[4] => WP_Post Object
(
[ID] => 25550
[post_author] => 6
[post_date] => 2021-05-20 15:39:53
[post_date_gmt] => 2021-05-20 13:39:53
[post_content] => On April 21, 2021, the European Commission presented a proposal with new rules for
[post_title] => Risk check for AI applications
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => risk-check-for-ai-applications
[to_ping] =>
[pinged] =>
[post_modified] => 2021-11-29 16:15:04
[post_modified_gmt] => 2021-11-29 15:15:04
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=26698
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[4] => WP_Post Object
(
[ID] => 25550
[post_author] => 6
[post_date] => 2021-05-20 15:39:53
[post_date_gmt] => 2021-05-20 13:39:53
[post_content] => On April 21, 2021, the European Commission presented a proposal with new rules for Why new rules?
AI is already widely used, often without us realizing it. MostWhich risk categories?
TheHow do you categorize AI products?
The committee has come up with a method for categorizing AI applications in one of the four risk levels. Its purpose is to provide security for companies and others. The risk is assessed based on the intended use. This means that the following factors are looked at: - the intended purpose - the number of people potentially affected - the dependence of the outcome - the irreversibility of the damageWhat are the consequences for high-risk AI systems?
Before these high-risk AI systems can be used, their compliance with the regulations must be investigated. This investigation must show that the AI system is compliant with the requirements regarding data quality, documentation and traceability, transparency, human supervision, accuracy and robustness. In case of some AI systems, a "Who will enforce these rules?
Member States will have to designate an authority to monitor compliance.Codes of Conduct
Suppliers of high-risk AI systems can create a voluntary code of conduct for the safe application of AI systems. The Commission is encouraging the industry to come up with these codes.Who is liable when importing AI systems?
The importer of AI systems into the EU is responsible for the imported AI system. It must ensure that the producer is compliant withWhat is the sanction?
Violation of these regulations can be sanctioned with a [post_title] => New European rules for Artificial Intelligence
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => new-european-rules-for-artificial-intelligence
[to_ping] =>
[pinged] =>
[post_modified] => 2021-05-20 15:44:50
[post_modified_gmt] => 2021-05-20 13:44:50
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=25550
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[5] => WP_Post Object
(
[ID] => 20406
[post_author] => 19
[post_date] => 2020-04-30 14:29:36
[post_date_gmt] => 2020-04-30 12:29:36
[post_content] => In veel bezwaar- en beroepsprocedures stellen belanghebbenden aantasting van privacy aan de kaak. In de meeste gevallen zonder succes. Er wordt in deze bezwaar- en beroepsprocedures een strak onderscheid gemaakt tussen bestuursrecht en privaatrecht. Dat wil zeggen dat privaatrechtelijke aspecten – zoals privacy – niet van belang zijn bij vergunningverlening. Dat is slechts anders in het geval van een zogenoemde ‘evidente privaatrechtelijke belemmering’. Dat er niet snel sprake is van zo’n evidente privaatrechtelijke belemmering, beschreef ik in een eerder artikel hierover. Uit dit artikel blijkt dat er twee eisen zijn:
[post_title] => New European rules for Artificial Intelligence
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => new-european-rules-for-artificial-intelligence
[to_ping] =>
[pinged] =>
[post_modified] => 2021-05-20 15:44:50
[post_modified_gmt] => 2021-05-20 13:44:50
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=25550
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[5] => WP_Post Object
(
[ID] => 20406
[post_author] => 19
[post_date] => 2020-04-30 14:29:36
[post_date_gmt] => 2020-04-30 12:29:36
[post_content] => In veel bezwaar- en beroepsprocedures stellen belanghebbenden aantasting van privacy aan de kaak. In de meeste gevallen zonder succes. Er wordt in deze bezwaar- en beroepsprocedures een strak onderscheid gemaakt tussen bestuursrecht en privaatrecht. Dat wil zeggen dat privaatrechtelijke aspecten – zoals privacy – niet van belang zijn bij vergunningverlening. Dat is slechts anders in het geval van een zogenoemde ‘evidente privaatrechtelijke belemmering’. Dat er niet snel sprake is van zo’n evidente privaatrechtelijke belemmering, beschreef ik in een eerder artikel hierover. Uit dit artikel blijkt dat er twee eisen zijn:
- Is er sprake van een privaatrechtelijke belemmering?
- Is die beperking evident zodat die in de weg staan aan vergunningverlening?
Wat speelde er in die zaak?
Er was door de gemeente Haarlem een vergunning verleend voor het realiseren van een dakterras op een aanbouw. De buren van de vergunninghouder zijn het niet eens met de verleende vergunning. De buren vrezen een aantasting van hun privacy door inkijk in de woonkamer vanaf het dakterras. Zij stellen dat er vanaf het dakterras rechtstreeks zicht is in hun woonkamer. De buren verwijzen naar artikel 5:50 BW. Daarin is bepaald dat het niet geoorloofd is binnen twee meter van de grenslijn van een erf vensters of andere muuropeningen, dan welk balkons of soortelijke werken te hebben voor zover deze op dit erf uitzicht geven. De gemeente stelt dat er van een evidente privaatrechtelijke belemmering geen sprake is, terwijl de buren stellen dat daarvan wel sprake is. Met het uitzicht wordt inbreuk gemaakt op hun privacy en tevens wordt gehandeld in strijd met het verbod van artikel 5:50 BW.Wat zegt de hoogste bestuursrechter?
De hoogste bestuursrechter verwijst eerst naar de vaste rechtspraak waaruit blijkt dat van een evidente privaatrechtelijke belemmering niet snel sprake is. Vervolgens overweegt de bestuursrechter: “Op basis van de door partijen overgelegde en ter zitting getoonde foto’s stelt de Afdeling vast dat er vanaf de korte zijde van het door vergunninghouder gewenste balkon rechtstreeks zicht is op het naburige erf van appellanten. Omdat de korte zijde van het balkon rechtstreeks uitkijkt op dit erf, volgt de Afdeling het college niet in de stelling dat er om een hoekje moet worden gekeken en een kwartslag moet worden gedraaid om zicht te hebben op dit erf. De korte zijde van het voorziene balkon bevindt zich binnen twee meter van de grens met het erf van appellanten en heeft een open hekwerk met een hoogte van 1,20 m. Daarmee is er sprake van zicht op het erf binnen 2 m van de grenslijn als bedoeld in artikel 5:50 van het BW. Vanaf het balkon is er door de twee glazen lichtkoepels in het dak van de aanbouw van appellanten in ieder geval ’s avonds met kunstmatige verlichting aan rechtstreeks zicht in hun woonkamer. Daargelaten of het zicht vanwege de bolling van de lichtkoepels overdag beperkt is, levert ook zicht dat wegens verlichting in de woonkamer beperkt is tot de avonduren, rechtstreeks zicht op als bedoeld in artikel 5:50 van het BW. Aangezien in het bouwplan geen voorzieningen zijn opgenomen om het rechtstreekse zicht weg te nemen, levert het bouwplan strijd op met artikel 5:50 van het BW. Dit betekent dat sprake is van een evidente privaatrechtelijke belemmering die aan vergunningverlening voor het bouwplan in de weg staat. De rechtbank heeft dit niet onderkend.”Conclusie en relevantie voor de praktijk
Er is dus sprake van een privaatrechtelijke belemmering. Maar dat niet alleen, de belemmering staat ook in de weg aan vergunningverlening. De belemmering is ‘evident’. De gemeente had de vergunning dus niet mogen verlenen. De reden is dat er niet voldaan is aan de eis van artikel 5:50 BW. Uit deze uitspraak blijkt dat privaatrechtelijke belemmeringen dus zeker van belang kunnen zijn bij vergunningverlening. Dat geldt in het bijzonder voor dit soort ‘harde normen’ die privacy beschermen. Dit soort beperkingen in het burenrecht zal een gemeente dus in de besluitvorming – zeker in bezwaar – moeten meenemen. In een eerdere blog ben ik hier wat verder op ingegaan en heb ik meerdere voorbeelden hiervan genoemd. BG.legal zal deze ontwikkelingen nauwgezet volgen. Heeft u een vraag over privacy of een evidente privaatrechtelijke belemmering? Neem dan gerust vrijblijvend contact met mij op. Rutger Boogers, Advocaat, specialist omgevingsrecht [post_title] => Aantasting van privacy reden om vergunning te weigeren? Jazeker!
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => aantasting-van-privacy-reden-om-vergunning-te-weigeren-jazeker
[to_ping] =>
[pinged] =>
[post_modified] => 2020-04-30 14:29:36
[post_modified_gmt] => 2020-04-30 12:29:36
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=20406
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[6] => WP_Post Object
(
[ID] => 19971
[post_author] => 26
[post_date] => 2020-03-30 13:50:57
[post_date_gmt] => 2020-03-30 11:50:57
[post_content] => Data breaches are any occurrences related with the security of personal data, including the loss, alteration or unauthorized disclosure. The definition under the GDPR includes both deliberate acts, such as hacker attacks; or accidents, such as the loss of a pen drive by an organization employee.
Because of the GDPR obligation to notify the authorities, we are aware that data breaches recently happened in big companies like Uber and Facebook, which have huge potential and technical skills to invest in security measures. Therefore, it seems that it does not matter the sector, if the company is big or small, the main question is not if a data breach will happen, but when it will happen.
Contact us (e-mail) in order to receive our paper with advice regarding action plans to prevent and deal with data breaches.
[post_title] => Aantasting van privacy reden om vergunning te weigeren? Jazeker!
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => aantasting-van-privacy-reden-om-vergunning-te-weigeren-jazeker
[to_ping] =>
[pinged] =>
[post_modified] => 2020-04-30 14:29:36
[post_modified_gmt] => 2020-04-30 12:29:36
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=20406
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[6] => WP_Post Object
(
[ID] => 19971
[post_author] => 26
[post_date] => 2020-03-30 13:50:57
[post_date_gmt] => 2020-03-30 11:50:57
[post_content] => Data breaches are any occurrences related with the security of personal data, including the loss, alteration or unauthorized disclosure. The definition under the GDPR includes both deliberate acts, such as hacker attacks; or accidents, such as the loss of a pen drive by an organization employee.
Because of the GDPR obligation to notify the authorities, we are aware that data breaches recently happened in big companies like Uber and Facebook, which have huge potential and technical skills to invest in security measures. Therefore, it seems that it does not matter the sector, if the company is big or small, the main question is not if a data breach will happen, but when it will happen.
Contact us (e-mail) in order to receive our paper with advice regarding action plans to prevent and deal with data breaches.
Introduction: Definition and Obligations under the GDPR
Data breaches are any occurrences related with the security of personal data, including the loss, alteration or unauthorized disclosure. The definition under the GDPR includes both deliberate acts, such as hacker attacks; or accidents, such as the loss of a pen drive by an organization employee. In accordance with Articles 33 and 34 of the GDPR, the responsible for determining the purposes and means of personal data processing (“Controller”) has the obligation to communicate the data breaches to the competent data protection authority (“DPA” or “Authority”) within 72 hours after becoming aware of it and the individuals affected in reasonable time. However, not all of them shall be notified. It shall be analysed if the data breach is likely to result in a risk to the rights and freedoms of any individuals in order to meet the requirement to notify the DPA. On the other hand, the data breach shall be likely to result not only in a risk, but a high risk for the rights and freedoms, in order to require communication to the data subjects. Because of the obligation to notify the Authorities, we are aware that data breaches recently happened in big companies like Uber and Facebook, which have huge potential and technical skills to invest in security measures. Therefore, it seems that it does not matter the sector, if the company is big or small, the main question is not if a data breach will happen, but when it will happen. In this regard, the first important point to mention is the fact that the notification of a data breach does not automatically represent that the company will receive a fine. The European DPAs haven been considered if the security measures in place before the data breach were reasonable in order to prevent data breaches and, when positive, the investigations were concluded without further consequences for the Controllers, except to review and reinforce its security policies. Another option, if the company is in doubt about the risks posed by the data breach, is to notify the DPA in order to receive guidance in relation to the incident. There is also no penalty for the notification of incidents that are end up considered data breaches unlikely to result in risk and, therefore, would not be required to be notified.Prevention
Besides to the adoption of organisational and technical measures to avoid intrusions in the systems, as well to ensure security in the processes, it is relevant to have a well-structured incident response plans to deal with data breaches when they occur. It is common that the first to identify irregularities are the employees without decision-making power in the organization. Normally such employees do not have an overview of the business and may not understand what risks are related with the incident leading to their decision not to communicate the incident for the superiors. Some employees will also not communicate the incident thinking that they may be considered responsible for the problem. Even when they decide to communicate it, without a defined response plan, the communication flow is normally disorganized and inefficient. In view of the above, one of the basic requirements of an effective response plan is the obligation of communication of operational irregularities related to data protection by employees, as well as the provision of disciplinary measures for omitting any information related to an incident. In addition, it will be necessary to establish a well-structured communication flow leading the information to someone with decision-making power inside of the organization, which may, finally, bring the matter to a pre-selected interdisciplinary committee for data breach situations. Since service providers considered data processors (“Processor”) have the responsibility under the GDPR to inform any data breach to the Controller, the incident response plans shall also include them. It is recommended to include who in the organization shall be informed by the Processor and in which manner.Communication to Authorities and Data Subjects
GDPR establishes the tasks and powers of the National DPAs, which includes the promotion of public awareness regarding data protection, awareness of Controllers and Processors in relation to the compliance with the GDPR, giving advice on processing operations, among others. In this sense, it is important to highlight that the Controller may benefit from the notification obligation to the national DPA in order to have guidance in how to remediate the risks of a data breach, but also and preferable, before any data breach occurs. The GDPR sets forth the following minimum content to be included in the notification: (i) description of the data breach, including the categories and number of individuals concerned; (ii) contact details of the Data Protection Office or other point of contact inside of the organization; (iii) description of potential consequences of the data breach; and (iv) description of the measures taken or proposed in order to mitigate the possible risks. Despite the minimum content, even if the organization still do not have all the respective information available, the guidelines of the national DPAs indicate to notify the Authority within 72 hours after becoming aware of the incident in order to comply with the timely notification requirement. The lack of the minimum content shall not hinder the timely data breach notification by the Controller. Even after the first notification, it will be possible to complement, amend and even correct the previous information provided together with the reasons of delay to provide such information. This is the recommendation aiming to have Controllers and competent DPAs working together against the risks of the data breach since the first stages. The data breach communication to the data subjects should contain at least the same elements of the notification to the Authority, except for information of the categories and number of individuals concerned which are not required. The main difference between the data breach notification to the authority and the data breach communication to the data subject is that, in the last one, it shall be written in clear and plain language. In view of this specificity, it is recommendable to involve an interdisciplinary team with representants of different areas of the organization, such as the legal team, which will advise in relation to the minimum requirements of the GDPR for this communication; the Information Technology team, which analyses the technical details of the incident; and the communication and marketing team, which have the ability to choose the best strategy to communicate the data breach to the affected persons and write it in a easily understandable manner. In this regard, the involvement of an interdisciplinary team is recommended also in the occasion of the notification to the authority, but it is seems to be even more important in the elaboration of the communication to the data subjects. In case the individual communication to each affected data subject involve disproportionate effort to the Controller, the GDPR provides that it is possible to make public announcements considered equally effective. To achieve this purpose, the interdisciplinary team mentioned above will need to study the best strategy to deliver the communication ensuring its effectiveness.Mitigation Measures
The GDPR also exempts the necessity to the data breach communicate to data subjects when the Controller has taken measures which neutralize the risks of the data breach. In order to prevent the risks of data breaches, it is recommendable to apply encryption or other techniques avoiding the access of personal data by non authorized individuals. After the data breach, other measures are considered by the DPAs. Besides to a correct data breach notification to the competent Authority and communication to the data subjects, the following measures are considered by DPAs as best practices to deal with data breaches:- Avoiding negotiation with criminal hackers involved in the data breach;
- application of disciplinary measures to employees involved in the data breach in order to avoid reoccurrence or spreading of personal data in power of this employees;
- opening of disciplinary and judicial proceedings for the same purpose mentioned in item “ii” and for repairing damages;
- hiring of forensic services when in doubt of a data breach related with the processing activities by a Processor;
- full internet research with cybersecurity specialists in order to analyze if the personal data was affected, including in the deep web;
- mandatory change of relevant passwords;
- collection of correspondences or request erasing of online messages sent to the wrong address;
- in case of lack of internal expertise related with hacker attacks, seek external advisory;
- review internal processes in general and raise the employees awareness, specially in relation to that type of data breach.
Conclusion
In view of the above, it is important to highlight that the occurrence of a data breach does not necessarily means the violation of the GDPR and application of penalties by the competent DPA. If the organization have appropriate organisational and technical measures in place, including an incident response plan, as well as adopt measures in order to mitigate the data breach after it happens, the administrative procedures before the DPA may be concluded without further consequences to the organization. In addition, the organization may benefit from guidance of the DPA and from the data breach experience in order to avoid future data breaches of the same nature. [post_title] => Data breaches under the GDPR [post_excerpt] => [post_status] => publish [comment_status] => open [ping_status] => open [post_password] => [post_name] => data-breaches-under-the-gdpr [to_ping] => [pinged] => [post_modified] => 2020-03-30 13:53:05 [post_modified_gmt] => 2020-03-30 11:53:05 [post_content_filtered] => [post_parent] => 0 [guid] => https://bg.legal/?p=19971 [menu_order] => 0 [post_type] => post [post_mime_type] => [comment_count] => 0 [filter] => raw ) [7] => WP_Post Object ( [ID] => 19751 [post_author] => 6 [post_date] => 2020-03-12 11:12:25 [post_date_gmt] => 2020-03-12 10:12:25 [post_content] => The U.S. Food and Drug Administration (FDA) has recently authorized marketing of a software based on Artificial Intelligence (AI) intended to guide medical professionals in capturing quality cardiac ultrasounds used to identify and treat heart diseases. The Software Caption Guidance is based on a machine learning technology that differentiates quality images and non-acceptable images. In addition, it is connected with an AI based interface designed to give described commands to untrained professional about the operation of the ultrasound probe in order to capture relevant images. Considering that heart diseases are one of the most known causes of death in the world and this technology promotes access to effective cardiac diagnostics by professionals without prior experience with ultrasound technologies, it is a potential lifesaving tool. Several AI based medical devices has been analysed and approved by the FDA since 2018. New instruments were included in the premarket submission in order to analyse the transparency and accuracy of the respective AI algorithms. This was discussed in the FDA’s paper launched in April, 2019 ““Proposed Regulatory Framework for Modifications to Artificial Intelligence/Machine Learning (AI/ML)-Based Software as a Medical Device (SaMD) - Discussion Paper and Request for Feedback”. This movement has encouraged even more investments on the sector and has been influencing the European scenario. The European Commission is working on the development of AI regulation in multi-dimensional perspectives and it seems to have concluded why and how regulate it through the publication of “Ethics Guidelines for Trustworthy AI” in April, 2019 by the European Commission’s High-level Expert Group on Artificial Intelligence. The recommendations are related with the principles of ethics, lawfulness and robustness from a technical and societal perspectives. Specifically in relation to the health sector, the Regulation EU 2017/745 on Medical Devices (Medical Devices Regulation), which will be fully applicable in May 2020, provides that software programs created with the clear intention to be used for medical purposes are considered medical devices. Therefore, AI based health technologies helping to decide on treatment of diseases through prediction or prognosis usually fall under this definition. In this regard, while different sectors are pressing for a practical regulation for AI, the European health sector has been mentioned as one possible case in which pre existing regulation, such as the Medical Device Regulation and its certification process, may be enough to keep up with AI based technologies. Despite the fact that medical devices are regulated by national authorities, the European Medicine Agency (EMA) is the responsible for assessment, authorization and supervision of certain categories in accordance with the European legislation. Considering the potential of innovative technologies to transform healthcare, including AI based medical devices, as well as the risks it raises, EMA has joined an European task force involving the matter[1] and has launched its main strategic goals[2], including the exploitation of digital technologies and artificial intelligence in decision making. Besides to develop expertise to engage with digital technology, artificial intelligence and cognitive computing, EMA’s idea is to create an AI test laboratory to explore application of AI based technologies which support data driven decisions. In general, the main European concerns about AI are related with transparency and accountability considering the complexity of the respective algorithms, but specially, the identification of unlawful biases and prejudicial elements. In this regard, health data breaches and AI decision making based on sensitive data such as health data may lead to discrimination and is considered of a huge risk. In addition, the Medical Devices Regulation mentions requirement such as informed consent, transparency, access to information and provision of accessible and essential information about the device to the patient. Therefore, its recommendable at least to demonstrate the efforts to overcome the challenges related with AI mentioned above in the submissions for approvals of medical devices to EMA. It can be tackled by presenting predictable and verifiable algorithms, a clear understanding of the categories of data used in the project and the implementation of regular audits and procedures to avoid discrimination, errors and inaccuracies. In view of the above, EMA seems still be searching an adequate approach to ensure that AI based innovative technologies are effective and appropriate to support medical decisions, as well as to fit AI in the existing regulatory framework in a manner that these technologies are supported by the society. Notwithstanding, EMA has been supporting initiatives to explore AI and already approved investigations researches based on artificial intelligence, such as the pediatric investigation plan for PXT3003 by Pharnext company[3], which demonstrates it is open to discuss AI based projects. As included in a recent article written by Daniel Walch, director of groupement hospitalier de l’Ouest lémanique (GHOL) and by Xavier Comtesse, head of the first Think Tank in Switzerland and PHD in Computer Science: “Artificial intelligence will not replace doctors. But the doctors who will use AI will replace those who will not do it”. Therefore, it will be key to have a more practical approach in relation to the approval of AI medical devices for the promotion of innovation and trust in the European health sector, specially upon May, 2020, with the full applicability of the Medical Devices Regulation. [1] HMA-EMA Joint Big Data Taskforce https://www.ema.europa.eu/en/documents/minutes/hma/ema-joint-task-force-big-data-summary-report_en.pdf [2] EMA Regulatory Science to 2025 https://www.ema.europa.eu/en/documents/regulatory-procedural-guideline/ema-regulatory-science-2025-strategic-reflection_en.pdf [3] European Medicines Agency Agrees with Pharnext’s Pediatric Investigation Plan for PXT3003 https://www.pharnext.com/images/PDF/press_releases/2018.07.10_PIP_agreement_EN.pdf [post_title] => European Perspectives on AI Medical Devices
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => europese-perspectieven-op-ai-medische-hulpmiddelen
[to_ping] =>
[pinged] =>
[post_modified] => 2020-03-12 11:40:15
[post_modified_gmt] => 2020-03-12 10:40:15
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=19751
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[8] => WP_Post Object
(
[ID] => 18547
[post_author] => 6
[post_date] => 2019-10-21 14:31:31
[post_date_gmt] => 2019-10-21 12:31:31
[post_content] => At 20 October 2019, Jos van der Wijst gave a presentation about legal aspects of blockchain cases in food.
Jos is technology lawyer with a focus on the Food sector.
The presentation was part of the program of the Den Bosch Data Week and was held in the Jheronimus Academy of Data Science.
The next presentation of Jos will at the Agri Food Tech conference, 11 December 2019 in Den Bosch.
Jos will give a presentation about collaboration in tech innovations in Food.
The title of the presentation is: “Don’t let legal be a troublemaker in a collaboration”.
The slides of the presentation are available here.
[post_title] => European Perspectives on AI Medical Devices
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => europese-perspectieven-op-ai-medische-hulpmiddelen
[to_ping] =>
[pinged] =>
[post_modified] => 2020-03-12 11:40:15
[post_modified_gmt] => 2020-03-12 10:40:15
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=19751
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[8] => WP_Post Object
(
[ID] => 18547
[post_author] => 6
[post_date] => 2019-10-21 14:31:31
[post_date_gmt] => 2019-10-21 12:31:31
[post_content] => At 20 October 2019, Jos van der Wijst gave a presentation about legal aspects of blockchain cases in food.
Jos is technology lawyer with a focus on the Food sector.
The presentation was part of the program of the Den Bosch Data Week and was held in the Jheronimus Academy of Data Science.
The next presentation of Jos will at the Agri Food Tech conference, 11 December 2019 in Den Bosch.
Jos will give a presentation about collaboration in tech innovations in Food.
The title of the presentation is: “Don’t let legal be a troublemaker in a collaboration”.
The slides of the presentation are available here.
 [post_title] => Den Bosch Data Week: Practical experiences Blockchain and Food
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => den-bosch-data-week-practical-experiences-blockchain-and-food
[to_ping] =>
[pinged] =>
[post_modified] => 2019-10-30 16:40:07
[post_modified_gmt] => 2019-10-30 15:40:07
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=18547
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[9] => WP_Post Object
(
[ID] => 12018
[post_author] => 6
[post_date] => 2018-03-27 10:47:18
[post_date_gmt] => 2018-03-27 08:47:18
[post_content] =>
Bogaerts & Groenen Advocaten will organize a meeting on ‘How block chain can be used in the AgriFood chain'
When: Tuesday, June 12, 2018
Where: Den Bosch
Topic
In four presentations the practical applications of block chain for the AgriFood will be outlined.
With block chain technology the complete food production chain could be made transparent. With block chain technology insight can be given from which farm a product originates, who has processed the product, who transported the product, who packaged the product and how the product ended up on the shelf of the supermarket. In this way block chain technology could contribute to sustainable production and transparent supply chains. In this way block chain technology could contribute to the restoration of consumer confidence in food.
But to what extent is this only theory? To what extent can this be used in practice in the Agri Food sector?
[post_title] => Den Bosch Data Week: Practical experiences Blockchain and Food
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => den-bosch-data-week-practical-experiences-blockchain-and-food
[to_ping] =>
[pinged] =>
[post_modified] => 2019-10-30 16:40:07
[post_modified_gmt] => 2019-10-30 15:40:07
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=18547
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[9] => WP_Post Object
(
[ID] => 12018
[post_author] => 6
[post_date] => 2018-03-27 10:47:18
[post_date_gmt] => 2018-03-27 08:47:18
[post_content] =>
Bogaerts & Groenen Advocaten will organize a meeting on ‘How block chain can be used in the AgriFood chain'
When: Tuesday, June 12, 2018
Where: Den Bosch
Topic
In four presentations the practical applications of block chain for the AgriFood will be outlined.
With block chain technology the complete food production chain could be made transparent. With block chain technology insight can be given from which farm a product originates, who has processed the product, who transported the product, who packaged the product and how the product ended up on the shelf of the supermarket. In this way block chain technology could contribute to sustainable production and transparent supply chains. In this way block chain technology could contribute to the restoration of consumer confidence in food.
But to what extent is this only theory? To what extent can this be used in practice in the Agri Food sector?
- What is already clear and what is not?
- How can AgriFood companies use this technology?
- What are opportunities and threats?
- What are the experiences of other Food companies with block chain technology
- What are the legal issues of block chain technology
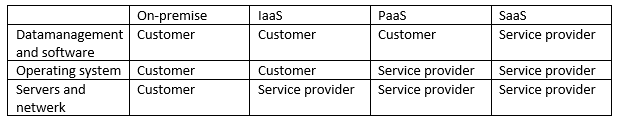
Software as a Service (SaaS)
The first type is the SaaS. A SaaS is like a goldfish,Platform as a Service (PaaS)
A PaaS is more open than a SaaS. You can compare a PaaS to a dog,Infrastructure as a Service (IaaS)
An IaaS offers the most freedom you can have without owning servers. It's like having a litter of puppies,On-premise
If you want to take care of everything yourself then you can purchase theComparison
The table at the top of this article provides an overview of which party is responsible for what. Basically, as a customer, you should be able to expect that the part which the service provider takes care of will work properly. If not, then your service provider should be liable for the downtime within the contractual limits. For example,Conclusion
The different aaS forms each have their advantages and disadvantages. Also legally. How much responsibility and risk are you willing to accept? Does this fit with the corporate/professional liability insurance you have? For
[post_title] => Choices when choosing cloud services
[post_excerpt] =>
[post_status] => publish
[comment_status] => open
[ping_status] => open
[post_password] =>
[post_name] => choices-when-choosing-cloud-services
[to_ping] =>
[pinged] =>
[post_modified] => 2021-11-09 10:20:48
[post_modified_gmt] => 2021-11-09 09:20:48
[post_content_filtered] =>
[post_parent] => 0
[guid] => https://bg.legal/?p=27674
[menu_order] => 0
[post_type] => post
[post_mime_type] =>
[comment_count] => 0
[filter] => raw
)
[comment_count] => 0
[current_comment] => -1
[found_posts] => 94
[max_num_pages] => 10
[max_num_comment_pages] => 0
[is_single] =>
[is_preview] =>
[is_page] =>
[is_archive] => 1
[is_date] =>
[is_year] =>
[is_month] =>
[is_day] =>
[is_time] =>
[is_author] =>
[is_category] =>
[is_tag] =>
[is_tax] => 1
[is_search] =>
[is_feed] =>
[is_comment_feed] =>
[is_trackback] =>
[is_home] =>
[is_privacy_policy] =>
[is_404] =>
[is_embed] =>
[is_paged] => 1
[is_admin] =>
[is_attachment] =>
[is_singular] =>
[is_robots] =>
[is_favicon] =>
[is_posts_page] =>
[is_post_type_archive] =>
[query_vars_hash:WP_Query:private] => f36c974e47ba45ada4b7a3f34f42cc44
[query_vars_changed:WP_Query:private] => 1
[thumbnails_cached] =>
[allow_query_attachment_by_filename:protected] =>
[stopwords:WP_Query:private] =>
[compat_fields:WP_Query:private] => Array
(
[0] => query_vars_hash
[1] => query_vars_changed
)
[compat_methods:WP_Query:private] => Array
(
[0] => init_query_flags
[1] => parse_tax_query
)
[query_cache_key:WP_Query:private] => wp_query:71194f89b6571aa126aed31ad230d8f9:0.95852300 17546709680.28324000 1754670969
[tribe_is_event] =>
[tribe_is_multi_posttype] =>
[tribe_is_event_category] =>
[tribe_is_event_venue] =>
[tribe_is_event_organizer] =>
[tribe_is_event_query] =>
[tribe_is_past] =>
[tribe_controller] => Tribe\Events\Views\V2\Query\Event_Query_Controller Object
(
[filtering_query:Tribe\Events\Views\V2\Query\Event_Query_Controller:private] => WP_Query Object
*RECURSION*
)
)
09 Nov 2021
08 Nov 2021
17 Aug 2021

30 Mar 2020
12 Mar 2020


[theme-my-login default_action=login login_template=tml-login-form.php]
[theme-my-login show_title=0 default_action=register register_template=tml-register-form.php]